Projects
Cancer is a complex disease that impacts millions of lives across the globe. According to the International Agency for Research on Cancer (IARC),
“The anticipated rise in the global burden of cancer by 2045 is substantial, with the number of cases expected to reach 32.6 million, up from 20 million in 2020. Similarly, cancer mortality rates are projected to increase significantly, with 16.9 million deaths predicted by 2045 compared to 9.74 million in 2020. These projections underscore the growing challenge of managing and mitigating cancer’s impact on global health.”
The disease is compounded by issues, such as rapid urbanization, Improved Detection, ageing population, inactive and unhealthy lifestyles, indoor and outdoor air pollution, majorly impacting the middle-to-low socio-economic countries including India.
In 2006, the National Institute of Health (NIH) launched The Cancer Genome Atlas (TCGA) to explore the entire spectrum of genomic changes involved in human cancer. The project molecularly characterized over 20,000 primary cancer and matched normal samples from 33 cancer types.

Why Indian Cancer Genome Atlas (ICGA)?
TCGA, established in the USA, has data primarily from the local US population and does not include enough Indian samples. The Indian population has a unique genetic diversity that differs significantly from Western populations. This genetic diversity can influence the development, progression, and response to treatment of various cancers. The types and prevalence of cancers in India differ from those in other countries. For example, cancers of the oral cavity, cervix, and gallbladder are more common in India. The ICGA can help identify the genetic and environmental factors contributing to these differences. By understanding the genetic variations specific to the Indian population, the ICGA can help clinicians and researchers develop more effective, personalized treatment plans and therapies.
Cancer is devastating for individuals and families and is a major health burden on society, especially in middle-to-low-income populations in South Asian countries such as India, it is the need of the hour to conduct such large-scale studies to gain more insights into this disease and its prevention.
Objectives
In this public health effort, high-quality meta-data of cancer patients and biospecimens (blood, cancer tissues) representing various clinical scenarios are being ethically collected from various geographical regions of India. Big-data generated after multi-omics profiling will be curated and analyzed for correlation with clinicopathological profiles. Such curated databases will be then open-sourced to the Indian and global cancer research communities.
ICGA Ecosystem
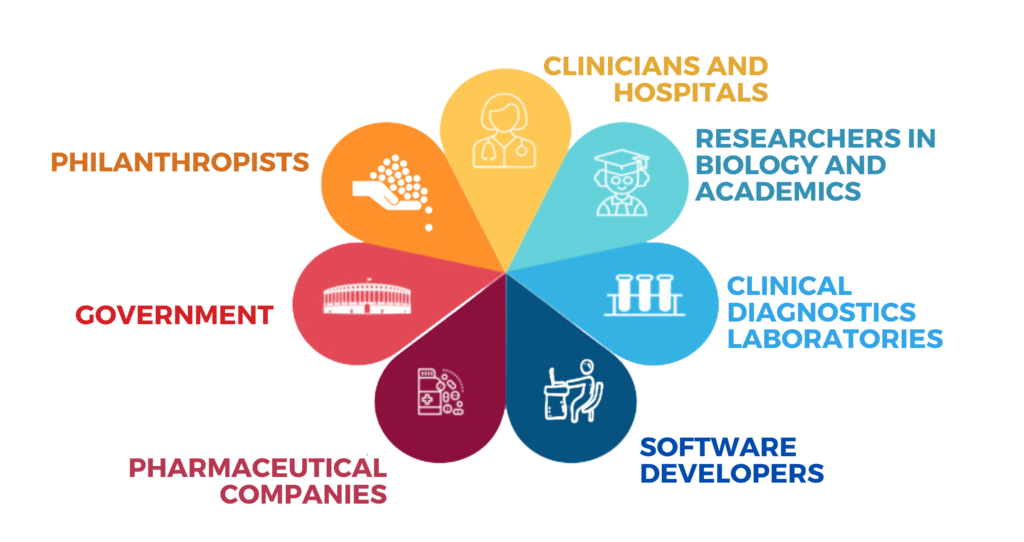
Given the multi-disciplinary nature of the project, domain experts from several inter-linked biomedical research domains are actively engaged in the ICGA project.
Strategy
The successful creation and quality of the proposed open-source multi-omics database of Indian cancers is entirely dependent on the uniformity, sanctity, and integrity of the meta-data and biospecimens collected from various geographical locations. Hence, a pan-India consortium of partners is being established, which operates as a ‘hub-and-spoke’ model. The work plan comprises 5 major representative domains:
- Primary data and sample collection centers in regional cancer hospitals/clinics (based on a pan-India consortium)
- Central biobank and sample processing unit
- Database and analytics center
- Multi-omics data-generation center
- Capacity building: short courses and hands-on training workshops on all aspects of the project and more importantly, on effective and timely use of the meta-data collected as above for patient care
Operational Model

Potential Impact of ICGA on Cancer Research in India
- Generation of high-quality multi-omics data about Indian cancers
- Facilitating integration of local-context-specific molecular oncology principles into clinical cancer management in the near future
- Capacity building for long-term translational cancer research in India
- Boosting of precision oncology eco-system by focusing on innovation and Indigenous development of solutions to Indian problems
- Significant contribution to global cancer knowledge databases
- Fostering long-term international collaborations with focus on multi-omics research in South Asian cancers
- Generate important data that will impact cancer practices for global Indian diaspora